Tutorial 3: NOMAD Artificial Intelligence Toolkit
Time: February 2-3 & 9-10
NOMAD Developer: Luca Ghiringhelli & Luigi Sbailo
Registration is required
Description
In this tutorial we introduce the functionalities of the NOMAD AI Toolkit, the web-based framework for querying, filtering, and perform AI analysis on the data contained in the NOMAD Archive. The user interface is based on the jupyter notebook environment, which is becoming increasingly popular in scientific research. All showcase notebooks are written in Python (for the data analytics). Basic knowledge of the Python language (including the data-science libraries numpy and pandas) is advisable for a better interaction with the tutorial material. A well-done freely available crash-course on these topics is, for instance: https://www.youtube.com/watch?v=r-uOLxNrNk8 .
The tutorial is in two parts.
Topics covered in the first (February 2-3) part are:
- how to transfer a search done via the Archive GUI into a jupyter notebook
- how to perform queries within the AI-Toolkit jupiter notebooks, via the NOMAD API
- how to perform exploratory analysis of the retrieved data, including unsupervised machine learning
- how to visualize the results of the analysis in interactive plots and produce transparency/paper-quality images.
In the second part (February 9-10), the topics are:
- exploration of tutorial notebooks presenting textbook and newly introduced AI tools
- exploration of notebooks presenting published AI research on actual materials-science data
- how to contribute with new notebooks
Please note:
Besides applying the AI tools to the data already contained in the ever-growing NOMAD Archive, the participants are invited to apply such tools also to data provided by them. To this purpose, the data would need to be uploaded to the NOMAD Repository and already processed into the Archive. It is advisable to produce a dataset and relative DOI, in order to access efficiently exactly the desired data. It is also advisable to proceed with the upload a few days before the tutorial, in order to have the data available, e.g., on the second day of the first session (February 3).
Program
Second part (February 9-10, 2021):
On February 9, at 10 am CET, we will open the NOMAD zoom meeting room, open to all participants. Luca Ghiringhelli and Luigi Sbailò will introduce and then be available for Q&A and assistance on the following topics:
- Tutorial notebooks on state-of-the-art (and beyond) AI tools: the example of "Symbolic regression via compressed sensing"
- Notebooks on published AI methodologies and their topical applications in materials science: the example of "Identifying Domains of Applicability".
- Guidelines on managing own notebooks on AI-toolkit.
On February 10, the live Q&A session with Luca Ghiringhelli and Luigi Sbailò will be the main focus. From 10:00 to 13:00 CET, they will answer questions and provide assistance in the NOMAD zoom meeting room.
It is advisable to activate a NOMAD account. To the purpose, go to https://nomad-lab.eu/AItutorials, click "direct log in" and then "Register". If you have created already an account for the Repository, you do not need to create a new account, the NOMAD account is centralized. To check this, after clicking "direct log in" fill in the credential you use for the Repository and you should be able to access it.
Videos and Exercises
Introduction to NOMAD AI-toolkit and MetaInfo
The following video introduces the general idea of the NOMAD AI-toolkit and how to access and navigate its web interface. The video also introduces NOMAD MetaInfo, in order to understand its hierarchical structure.
Introduction to exploratory analysis of data
Before putting your hands on the data in the NOMAD Archive, it is recommended that you get acquainted with techniques for performing exploratory analysis of data. The following introductory video and the related jupyter notebook will present to you (AI) unsupervised learning techniques, in particular clustering and dimension reduction.
The notebook can be found here:
"Exploratory analysis of octet-binary compounds" at https://nomad-lab.eu/AItutorials
Direct link: https://analytics-toolkit.nomad-coe.eu/public/user-redirect/notebooks/tutorials/exploratory_analysis.ipynb
Exercises are provided within the notebook.
Querying the Archive
In the following video, the query to the NOMAD Archive and data retrieving is introduced in a jupyter notebook, ready for the AI analysis
The notebook can be found here:
"Querying the Archive and performing Artificial Intelligence modeling" at https://nomad-lab.eu/AItutorials
Direct link: https://analytics-toolkit.nomad-coe.eu/public/user-redirect/notebooks/tutorials/query_nomad_archive.ipynb
For this section of the tutorial, please stop before "Example of unsupervised machine learning: Clustering and dimension reduction".
Exercises:
Analyzing and visualizing the results
In the following video, the focus is on the "visualizer", an interactive tool made for visualizing the outcome of AI analysis as well as the atomic structures behind each data point.
The notebook is the same as in the previous step. Please, start at "Example of unsupervised machine learning: Clustering and dimension reduction".
Exercises:
Hints for trying to analyze data you have uploaded into the Archive
Here is an example of code to access a specific dataset by name:
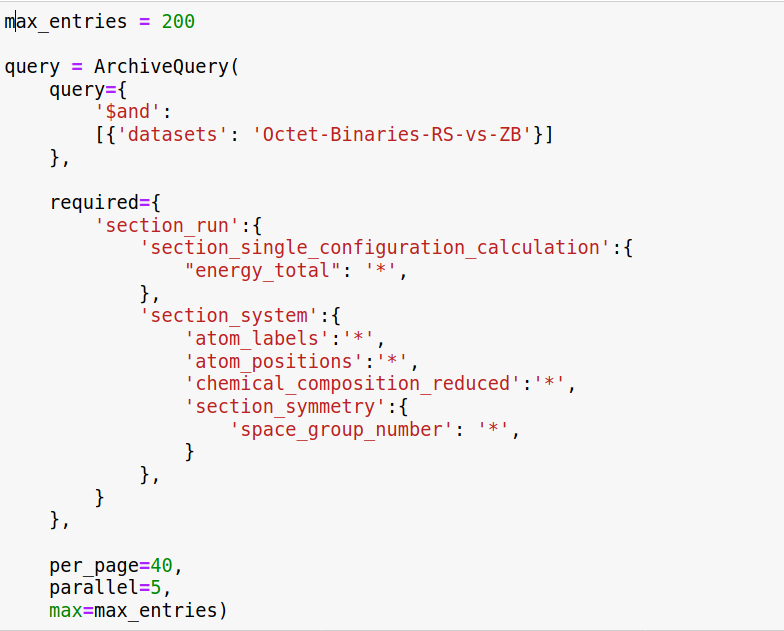
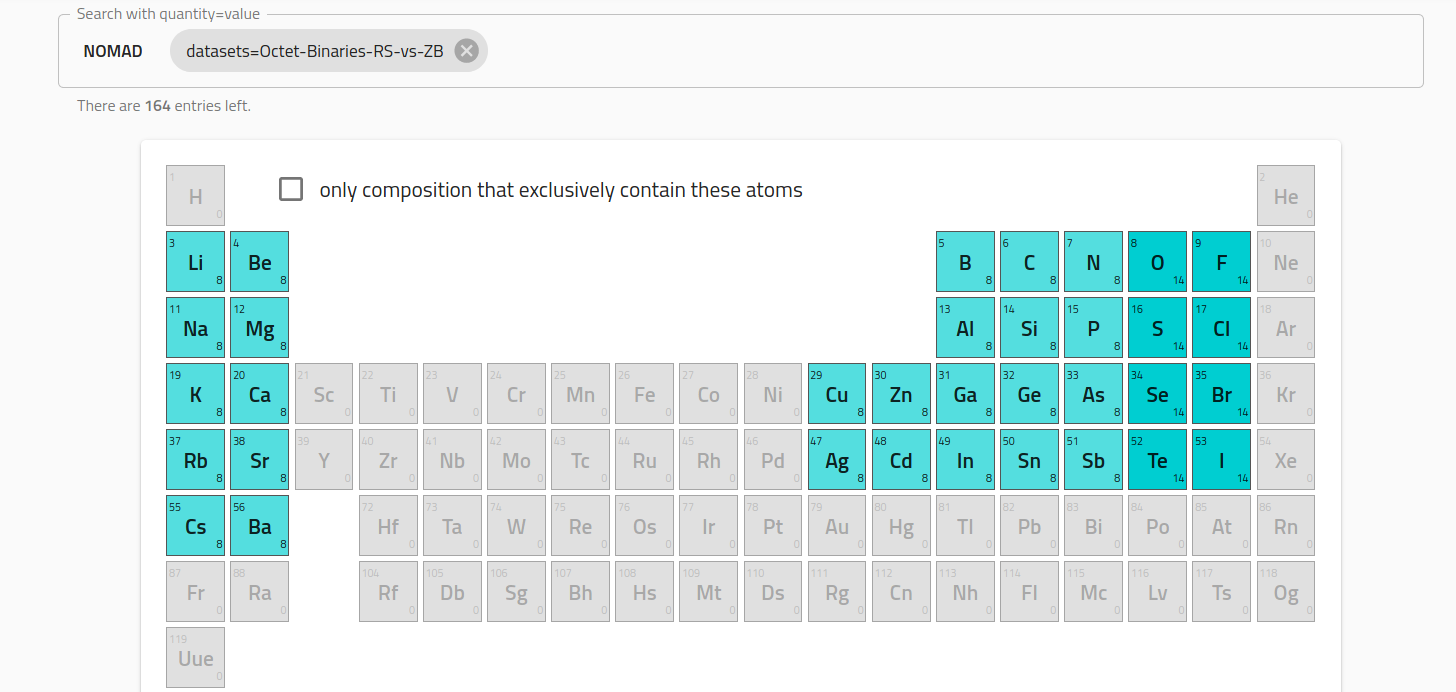
The same dataset must appear in the Archive-GUI search, e.g.:
Material for the session of February 9-10, 2021.
Tutorials on state-of-the-art (and beyond) AI tools
Focus on "Symbolic regression via compressed sensing: a tutorial"
Link to notebook:
https://analytics-toolkit.nomad-coe.eu/public/user-redirect/notebooks/tutorials/compressed_sensing.ipynb
Link to the introductory video:
https://youtu.be/73mLp6C2opY
Link to full lecture on symbolic regression combined with compressed sensing:
https://youtu.be/YJZm4xot4bM
https://youtu.be/KjPCMdWikBg
For more lecture material, see in general: \\
https://www.nomad-coe.eu/events/course-on-big-data-and-artificial-intelligence/lecture-materials
Jupyter notebooks on published AI methodologies and their topical applications in materials science
Focus on: "Identifying Domains of Applicability of Machine-Learning Models for Materials Science"
Link to notebook:
https://analytics-toolkit.nomad-coe.eu/public/user-redirect/notebooks/tutorials/domain_of_applicability.ipynb
Link to full lecture on subgorup discovery and domain of applicablity:
https://youtu.be/cizNEJypwao, https://youtu.be/uKEzs6koTcs