Big-Data Analytics for Materials Science
Luca M. Ghiringhelli
Mission
Mission and Research Topics
The availability of big data in materials science offers new routes for analyzing materials properties and functions and achieving scientific understanding. Finding structure in these data that is not directly visible by standard tools and exploitation of the scientific information requires new and dedicated methodology based on approaches from statistical learning, compressed sensing, and other recent methods from applied mathematics, computer science, statistics, signal processing, and information science.
Our aim is to develop (big)-data analytics tools for finding patterns, trends, analytical relationships in the materials science data.
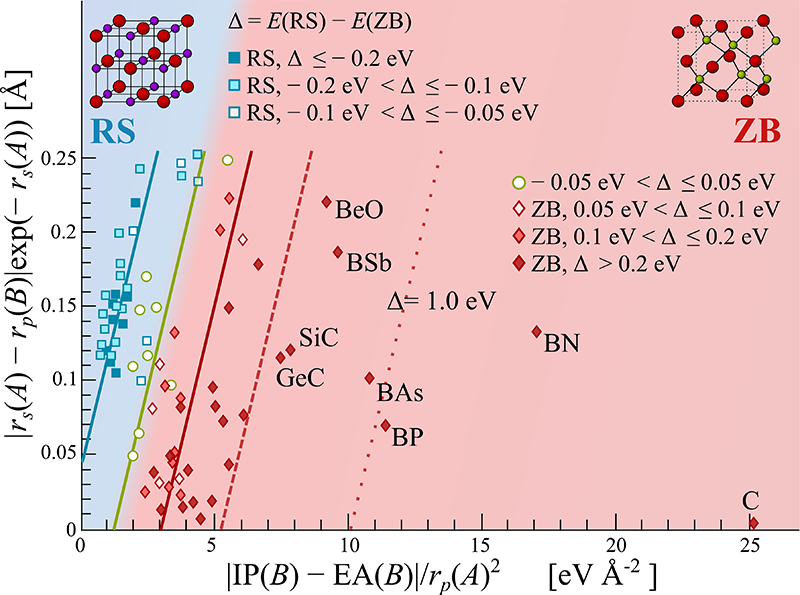
as predicted by a compressed-sensing based methodology developed in this group
We focus on these areas:
Compressed-sensing based Feature-Extraction Algorithms
Compressed sensing is a signal-processing technique that allows for the reconstruction of a signal from a sparse and uncorrelated sampling. Recently, we have been proposing a compressed-sensing based methodology (Ghiringhelli et al., PRL 2015) in order to identify functional dependencies, where the descriptor (the set of input variables of the functional dependence) is selected out of a dictionary of "well formed" candidate analytical expressions. Such candidates are constructed as non-linear functions of a set of basic "physically meaningful" features, called primary features.
We are developing and applying this methodology
- for learning analytical structure-property relationship in materials, such as transparent conducting sesquioxides, perovskites, sp-d ternaries, …
- as a dimensionality reduction approach that singles out the important coordinates out of a physically-motivated (redundant) dictionary. This is fundamental for the analysis of disordered systems (such as atomic clusters at finite temperature) and (catalyzed) chemical reactions.
- to fundamental theoretical chemistry issues, like the selection of an accurate basis set out of a redundant set of candidates or an alternative approach for the solution of the Kohn-Sham equations.
Exploratory Data Analysis
Together with Jilles Vreeken (Saarland University), we are developing methods for the automatic recognition of subsets of data with outstanding characteristics. This is used to find local rather than global predictive models, with the idea that materials with different physics have different structure-property relationships, for the same property.
NOMAD Analytics Toolkit
As part of the Novel Materials Discovery European Centre of Excellence, we are developing a web-based interface for the efficient querying and analysis (with various analytics methods) of the huge amount of data contained in the NOMAD Archive.
NOMAD Meta Info and Conversion Layer
The data uploaded by the dozens of research group contributing to the NOMAD Repository are the the raw inputs and outputs of electronic-structure (and force-field) codes. In order to be analyzed, the data have to be converted into a format that uses one convention for, e.g., units, zero base lines, and file formats. This is accomplished by defining a flexible and extensible metadata infrastructure, a mapping from the code-dependent to a physically intuitive, code-independent, representation. The v1.0 of NOMAD Meta Info has been released in the early 2016 and extensions are in progress.

![]()